Merkle Tree
ShareRing currently uses the Merkle tree algorithm to verify documents. Verifying digital identity poses risks to the user because identity documents are sensitive. A third party should only receive the necessary information to verify an individual, which is possible through the Merkle tree algorithm. The algorithm verifies the user's data through a cryptographic hash in a tree format, and the hash contains all information needed to verify the child nodes (leaves) of the tree.
When a third party sends a query to the blockchain, the Merkle tree algorithm only exposes the necessary leaves. The third party is given proof of the user's identity through the hash. Third parties receive information on a need-to-know basis, enhancing the user's digital security.
We use the Merkle tree algorithm to verify document proofs for the following reasons:
We only need to store a single hash string (32 bytes long) instead of the whole data. This small amount of information is enough to verify whether the document has been tampered with or not.
With Merkle root, we can verify multiple documents with just one root hash, significantly reducing both storage and transaction costs.
Every time we calculate a proof, we generate a unique hash. The unique hash ensures the document is completely identical per generation. No matter the hash, it always ties to the document content, and this means changing one bit of the content will fail the verification.
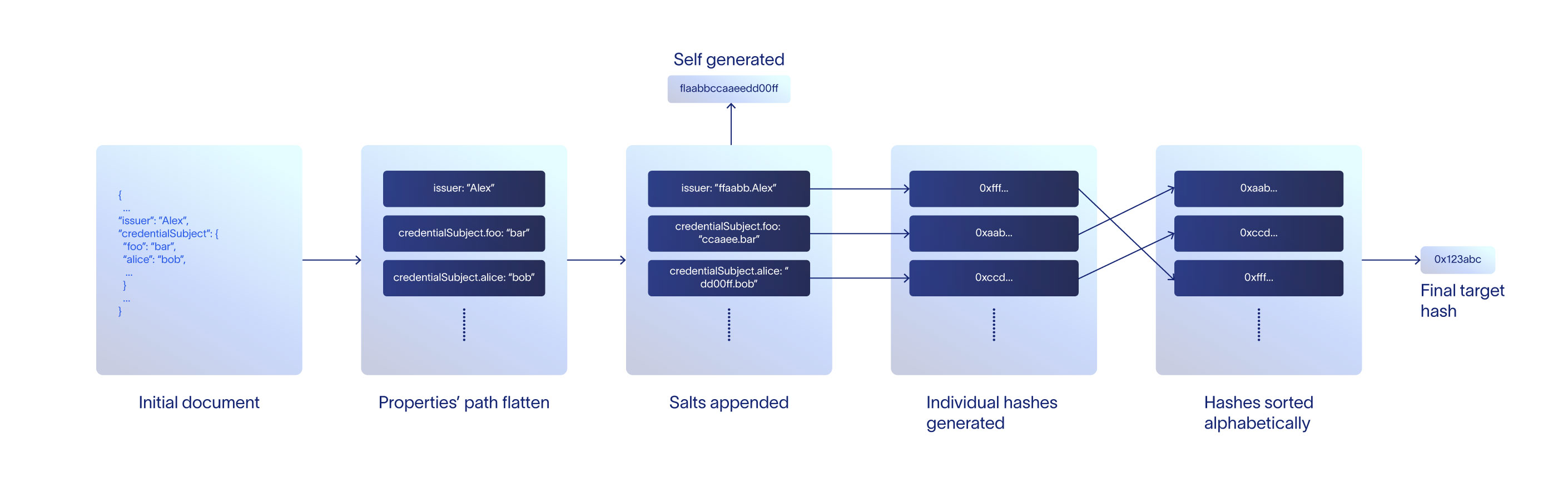
How Does the Hashing Work?
We generate a hash for every property, sort all the hashes alphabetically, combine them into one array and generate a final hash.
Below are detailed steps:
- List all properties' path (or "flatley-convention" keys) from the document and associate with its value.
- For each properties' path, compute a hash using the keccak256 algorithm (or SHA-3).
- Sort all the above hashes alphabetically and hash them all together. This step results in the final hash for the document.
- Merkle root is identical to the final hash in case of a single document. Otherwise, merkle root is computed by hashing all document hashes together.
Data Obfuscation
We want to keep all identity information private from the requester in specific scenarios. The Merkle Tree algorithm can hide certain pieces of information but still validate the authenticity of the entire block of data. Data obfuscation is helpful in scenarios where only certain information is required.